Antro rinkimų turo prognozė pasitelkiant neuroninius tinklus
Pirmiausia turiu įspėti: nemanau, kad reikėtų į gautus rezultatus žiūrėti labai rimtai. Neuroninio tinklo mokymui naudojau tik 2012-ų metų Seimo rinkimų apygardų duomenis, tad imtis labai nedidelė, o tai turėtų lemti ir gana nemažą paklaidą prognozėse. Galbūt tikslesnių rezultatų būtų galima tikėtis naudojant apylinkių, o ne apygardų duomenis.
Prognozuoti šių metų rezultatus iš 2012-ų metų duomenų nelengva ir dėl stipriai pasikeitusio partijų populiarumo: žalieji valstiečiai prieš ketverius metus nebuvo labai patrauklūs rinkėjams, o ir Skvernelio atsiradimas labai šią partiją pakeitė. Įdomu tai, kad Darbo partijos bei tvarkiečių kritimas iš aukštumų gana gerai atsispindi neuroninio tinklo rezultatuose: jiems prognozuojama laimėti mažiau apygardų nei jie šiuo metu pirmauja. Kad ir kaip ten būtų, gavau tokį rezultatą:
| Prognozė | Dabar pirmauja | |
|---|---|---|
| LVZS | 24 | 21 |
| TSLKD | 24 | 22 |
| LSDP | 9 | 10 |
| LRLS | 5 | 4 |
| LLRA | 3 | 3 |
| TT | 2 | 4 |
| KITI | 1 | 2 |
| DP | 1 | 3 |
| NEP | 2 | 2 |
Neuroninis tinklas „išmoko“, jog stiprus lenkų pirmavimas apygardoje dažniausiai lemia ir pergalę antrame ture. Algirdui Paleckiui pergalė neprognozuojama, nes istoriniai pernai metų duomenys rodo, jog „Frontui“ ne itin sekėsi – bet jo puikus pasirodymas pirmame ture tikriausiai buvo netikėtas ir daugeliui politikos analitikų. Keisčiausia prognozė, kuria sunku patikėti yra 52-oje Visagino-Zarasų apygardoje, kurioje antrame ture kausis Darbo partija su tvarkiečiais (pergalė prognozuojama Darbo partijai, nors stipriai pirmauja tvarkietis Dumbrava). Keistoka, bet gal ir logiška 40-osios Telšių apygardos prognozė, kur stipriai pirmaujantis darbietis turi mažai šansų atsilaikyti prieš valstietį Martinkų. Kaip jau minėjau, Darbo partijai šis modelis daug šansų nepalieka. Visas apygardų sąrašas su prognozuojamais nugalėtojais ir tikimybėmis, kad nugalės pirmaujantis.
Turint nedaug istorinių duomenų tikriausiai labiau pasitikėčiau politikos ekspertų prognozėmis konkrečioje apygardoje arba modeliuočiau tikimybes kiek kurios partijos rėmėjų ateis į antrą turą bei palaikys ne savo partijos kandidatą: būtent tokį modelį ruošia WebRobots komanda, kuri leido man pasinaudoti jų surinktais iš VRK duomenimis. Idėja patreniruoti neuroninį tinklą ir kilo susidūrus su problema ar nebūtų galima kaip nors statistiškai išskaičiuoti tikimybių, kiek, tarkim, socialdemokratų palaikytų konservatorių kandidatą jei jis būtų likęs prieš darbietį. Taip pat galima pažiūrėti į Vaidoto Zemlio prognozes.
Post Mortem
Rezutatai buvo stipriai kitokie, nei buvo tikimasi: daugiausiai prašauta (tikriausiai dėl to, kad 2012-aisias valstiečiai pasirodė ne itin įspūdingai) su LVŽS ir TSLKD. Tam tikros tendencijos buvo teisingos – Darbo partija, Tvarka ir Teisingumas bei Socialdemokratai iš tiesų gavo mažiau mandatų nei buvo pirmaujama po pirmo turo, tuo tarpu liberalai sugebėjo laimėti daugiau apygardų nei pirmavo po pirmo turo, tačiau šių pokyčių mastas buvo žymiai (žymiai žymiai) didesnis. Iš viso, neuroniniai tinklai sugebėjo atspėti 48 apygardas (67% tikslumas). Palyginimui – rankomis dėliotas Webrobots komandos modelis pasiekė 80% tikslumą. Tiesa, atmetus kai kuriuos nelogiškus neuroninio tinklo siūlymus, kurie plika akimi atrodė keisti ir pataisius prognozę Dainavos apygardoje dėl Vinkaus skandalo (ko iš 2012-ųjų duomenų niekaip nebuvo galima žinoti), buvo galima pasiekti maždaug 75% procentų tikslumą. Ne kažką, bet šis tas.
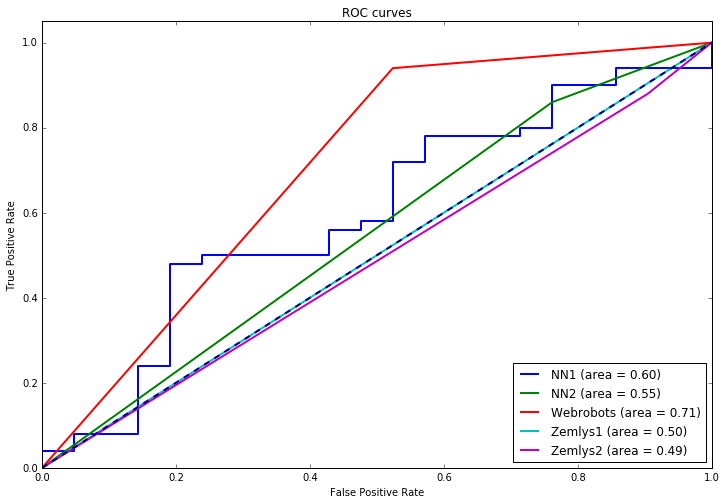
Skaičiuojant modelio patikimumą, dažnai žiūrimas plotas po Receiver Operating Characteristic (ROC) kreive (kuo gerenis modelis, tuo jis turėtų artėti link vieneto). Štai modelių palyginimai:
| Area under ROC curve | |
|---|---|
| Neuroninis tinklas (tikimybės) | 0.597143 |
| Webrobots modelis | 0.708095 |
| Neuroninis tinklas (binarinis) | 0.549048 |
| Laimės pirmaujantis 1 ture | 0.500000 |
| Laimės pirmaujantis daugiamandatėje | 0.487619 |
O čia pačios ROC kreivės:
Techniniai dalykai
Didžioji dalis tolimesnės informacijos bus įdomi tik visokiems programuotojams, nes tai tik techninės detalės.
Neuroninis tinklas su dviem paslėptais sluoksniais (iš 20 ir 10 neuronų) mokomas iš požymių, kurie yra 2012-ųjų metų vienmandačių apygardų pirmo turo rezultatai pagal partiją. y vektoriuje žymima 1 jeigu pirmaujantis pirmame ture laimėjo ir antrąjį bei žymima 0, jeigu nugalėtojas tarp turų pasikeitė. Kaštų funkcijoje pridedamas nedidelis reguliarizacijos parametras, nes be jo tinklas „persimoko“ (overfitting). Vėliau išmokytam tinklui duodami 2016-ų metų pirmo turo rezultatai (tiesa, šiek tiek pakeičiama partijų pavadinimai, kad jie kuo arčiau atitiktų 2012-ųjų metų partijų bei koalicijų pavadinimus) ir iš čia gaunama prognozė. Visa tai daryta su Python ir Tensorflow.