Įrašai su žyme „analizė“
Kur Lietuvoje tolimiausia iki ežero?
Kartais būna taip, kad kažkur netyčia nugirsti kokią minties nuotrupą ir po to ji vis tavęs nepalieka. Taip ir man nutiko: prieš kokį pusmetį ar net metus kažkas kažkur paklausė, kaip būtų galima sužinoti, kur yra artimiausias ežeras. Pagalvojau, kad atsakymą nesunku surasti šiek tiek pakračius atvirus geografinius ežerų duomenis. Bet tada pradėjo kirbėti nauja mintis: o kuri Lietuvos vieta yra toliausiai iki bet kokio ežero? Aišku, bėgo mėnesiai, programuoti nesiėmiau, bet klausimas vis tiek niežtėjo. Skaityti toliau…Duomenų bazių testavimas
Prieš keletą dienų užtikau patikusį straipsnį apie automatizuotus duomenų bazių testus. Programiniam kodui jau senokai tapo įprastinė praktika rašyti testus, bet duomenų bazių struktūra testuojama ne visada. Tiesa, gerai sutvarkytoje duomenų bazėje įmanoma sudėti daug saugiklių: stulpeliams uždėti apribojimus, išorinius raktus ir panašiai, tačiau bendras požiūris į duomenų teisingumą bei validumą vis tiek reikalingas. Autorius siūlo duomenis testuoti trijose vietose: pirminių šaltinių lygyje, tik juos sukėlus į duomenų bazę ir jau po verslo logikos transformacijų. Skaityti toliau…Neapdorotų duomenų nebūna
Yra toks gana gajus mitas, kad turint „žalius“ neapdorotus duomenis, galima nesunkiai padaryti objektyvias išvadas – juk neapdoroti duomenys turėtų kalbėti už save, jie neturėtų būti „sutepti“ šališkos žmogiškos nuomonės bei išankstinių nusistatymų. Kuo daugiau neapdorotų duomenų, tuo objektyvesnės išvados. Deja, visiškai neapdorotų duomenų nebūna. Jau pats faktas, kad kažkas juos rinko, reiškia, kad kažkas padarė sprendimą jais domėtis: o kodėl rinko būtent taip, o ne kitaip? Kodėl rinko tokius, o ne anokius? Skaityti toliau…Įsitraukimo metrikos veda klaidingu keliu
Jau prieš gerą pusmetį rašiau, kad kuo toliau, tuo labiau nesu patenkintas socialiniais tinklais: nors ir turiu išugdytą įprotį turint laisvą minutę įsijungti Facebook ar Instagram, retokai ten randu ką nors įdomaus. Dauguma istorijų tapę vienodos ir nebeįdomios, o Instagram nuotraukos atrodo lyg gamintos pagal vieną klišę. Jei netikite, užeikite į @insta_repeat profilį. Kodėl taip nutiko? Kodėl vis kompulsyviai norisi maigyti telefoną ir prasukti dar, ir dar, ir dar, ir dar vieną ekraną „turinio“ ir vis tiek nesijausi pasisotinusiu? Skaityti toliau…Lietuvos miestų gatvės pagal pasaulio šalis
Neseniai užtikau įdomią JAV bei kitų pasaulio didmiesčių gatvių orientacijos analizę, darytą vienu mano mėgstamiausių python modulių osmnx. Kadangi kodas viešas, tai buvo nesunku tą patį padaryti ir Lietuvos miestams. Kaunas ir Vilnius – gana chaotiški, o kitur vyrauja aiški kvartalinė sistema Kuo senesnis miestas, tuo didesnis senamiestis, o šie dažniausiai būna chaotiški. Naujesniuose miestuose daugiau vyrauja aiški kvadratinė kvartalinė sistema. Buvo įdomu tai, kad dažniausiai ji ne tiksliai šiaurės-pietų bei rytų-vakarų krypties, o apie 20 laipsnių pasukta pagal laikrodžio rodyklę (Alytus, Gargždai, Kretinga, Kėdainiai, Marijampolė, Mažeikiai, Neringa, Palanga, Telšiai – ypač Žemaitijoje). Skaityti toliau…Ben Goldacre – „I Think You’ll Find It’s a Bit More Complicated Than That“
Ben Goldacre turėjo šventą misiją: laikraščio the Guardian kassavaitinėje skiltyje jis nepailsdamas kritikuodavo žurnalistus bei mokslininkus, kurie nepaisydami statistikos dėsnių ar gerųjų mokslinio metodo praktikų pernelyg greitai peršokdavo prie toli siekiančių išvadų. Kliūdavo daugeliui, net tam pačiam the Guardian laikraščiui. Ši jo knyga yra kassavaitinės skilties straipsnių rinkinys. Mokslinius atradimus padaryti ne taip jau lengva: mokslininkams reikia nemažai statistikos žinių, o jų atradimus, kurie skelbiami moksliniuose žurnaluose, kritiška akimi turi peržiūrėti ir kiti mokslininkai. Skaityti toliau…Savaitė be nuosavo automobilio
Nežinau už kokius nuopelnus, bet šią savaitę buvau pakviestas prisijungti prie Europos judrumo savaitės (European Mobility Week) akcijos #ditchyourkeys ir ištisas septynias dienas atsisakyti savo automobilio. Tiesa, tam kad šis iššūkis nebūtų labai sudėtingas, akcijos rėmėjai Uber, Vilniaus Viešasis Transportas, Cyclocity, Citybee bei Spark suteikė galimybę šiomis dienomis jų paslaugomis naudotis nemokamai – tad per šią savaitę galėjau išbandyti visokiausius judėjimo po Vilnių būdus, kuriais iki šiol nesinaudojau. Už Vilniaus ribų šiomis dienomis neplanavau niekur vykti, o pasižiūrėjęs į savo judėjimo istoriją, supratau, kad mano geografija buvo ganėtinai ribota: visą laiką maliausi tarp namų Lazdynuose, senamiesčio ir dviejų klientų biurų. Skaityti toliau…Antro rinkimų turo prognozė pasitelkiant neuroninius tinklus
Pirmiausia turiu įspėti: nemanau, kad reikėtų į gautus rezultatus žiūrėti labai rimtai. Neuroninio tinklo mokymui naudojau tik 2012-ų metų Seimo rinkimų apygardų duomenis, tad imtis labai nedidelė, o tai turėtų lemti ir gana nemažą paklaidą prognozėse. Galbūt tikslesnių rezultatų būtų galima tikėtis naudojant apylinkių, o ne apygardų duomenis.
Prognozuoti šių metų rezultatus iš 2012-ų metų duomenų nelengva ir dėl stipriai pasikeitusio partijų populiarumo: žalieji valstiečiai prieš ketverius metus nebuvo labai patrauklūs rinkėjams, o ir Skvernelio atsiradimas labai šią partiją pakeitė. Įdomu tai, kad Darbo partijos bei tvarkiečių kritimas iš aukštumų gana gerai atsispindi neuroninio tinklo rezultatuose: jiems prognozuojama laimėti mažiau apygardų nei jie šiuo metu pirmauja. Kad ir kaip ten būtų, gavau tokį rezultatą:
| Prognozė | Dabar pirmauja | |
|---|---|---|
| LVZS | 24 | 21 |
| TSLKD | 24 | 22 |
| LSDP | 9 | 10 |
| LRLS | 5 | 4 |
| LLRA | 3 | 3 |
| TT | 2 | 4 |
| KITI | 1 | 2 |
| DP | 1 | 3 |
| NEP | 2 | 2 |
Neuroninis tinklas „išmoko“, jog stiprus lenkų pirmavimas apygardoje dažniausiai lemia ir pergalę antrame ture. Algirdui Paleckiui pergalė neprognozuojama, nes istoriniai pernai metų duomenys rodo, jog „Frontui“ ne itin sekėsi – bet jo puikus pasirodymas pirmame ture tikriausiai buvo netikėtas ir daugeliui politikos analitikų. Keisčiausia prognozė, kuria sunku patikėti yra 52-oje Visagino-Zarasų apygardoje, kurioje antrame ture kausis Darbo partija su tvarkiečiais (pergalė prognozuojama Darbo partijai, nors stipriai pirmauja tvarkietis Dumbrava). Keistoka, bet gal ir logiška 40-osios Telšių apygardos prognozė, kur stipriai pirmaujantis darbietis turi mažai šansų atsilaikyti prieš valstietį Martinkų. Kaip jau minėjau, Darbo partijai šis modelis daug šansų nepalieka. Visas apygardų sąrašas su prognozuojamais nugalėtojais ir tikimybėmis, kad nugalės pirmaujantis.
Turint nedaug istorinių duomenų tikriausiai labiau pasitikėčiau politikos ekspertų prognozėmis konkrečioje apygardoje arba modeliuočiau tikimybes kiek kurios partijos rėmėjų ateis į antrą turą bei palaikys ne savo partijos kandidatą: būtent tokį modelį ruošia WebRobots komanda, kuri leido man pasinaudoti jų surinktais iš VRK duomenimis. Idėja patreniruoti neuroninį tinklą ir kilo susidūrus su problema ar nebūtų galima kaip nors statistiškai išskaičiuoti tikimybių, kiek, tarkim, socialdemokratų palaikytų konservatorių kandidatą jei jis būtų likęs prieš darbietį. Taip pat galima pažiūrėti į Vaidoto Zemlio prognozes.
Post Mortem
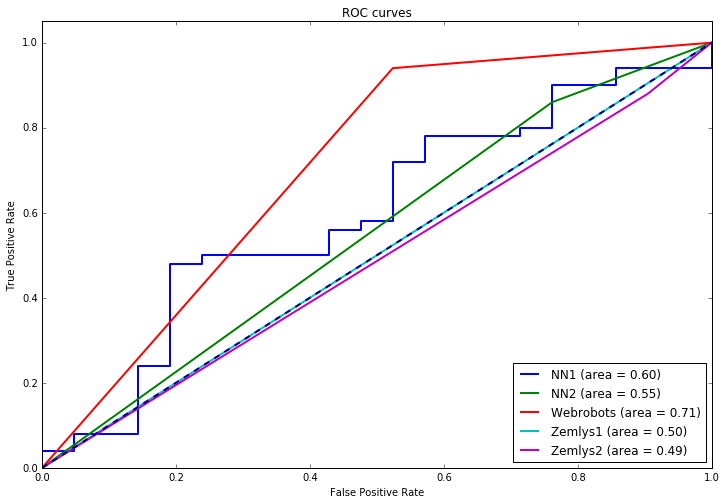
Rezutatai buvo stipriai kitokie, nei buvo tikimasi: daugiausiai prašauta (tikriausiai dėl to, kad 2012-aisias valstiečiai pasirodė ne itin įspūdingai) su LVŽS ir TSLKD. Tam tikros tendencijos buvo teisingos – Darbo partija, Tvarka ir Teisingumas bei Socialdemokratai iš tiesų gavo mažiau mandatų nei buvo pirmaujama po pirmo turo, tuo tarpu liberalai sugebėjo laimėti daugiau apygardų nei pirmavo po pirmo turo, tačiau šių pokyčių mastas buvo žymiai (žymiai žymiai) didesnis. Iš viso, neuroniniai tinklai sugebėjo atspėti 48 apygardas (67% tikslumas). Palyginimui – rankomis dėliotas Webrobots komandos modelis pasiekė 80% tikslumą. Tiesa, atmetus kai kuriuos nelogiškus neuroninio tinklo siūlymus, kurie plika akimi atrodė keisti ir pataisius prognozę Dainavos apygardoje dėl Vinkaus skandalo (ko iš 2012-ųjų duomenų niekaip nebuvo galima žinoti), buvo galima pasiekti maždaug 75% procentų tikslumą. Ne kažką, bet šis tas.
Skaičiuojant modelio patikimumą, dažnai žiūrimas plotas po Receiver Operating Characteristic (ROC) kreive (kuo gerenis modelis, tuo jis turėtų artėti link vieneto). Štai modelių palyginimai:
| Area under ROC curve | |
|---|---|
| Neuroninis tinklas (tikimybės) | 0.597143 |
| Webrobots modelis | 0.708095 |
| Neuroninis tinklas (binarinis) | 0.549048 |
| Laimės pirmaujantis 1 ture | 0.500000 |
| Laimės pirmaujantis daugiamandatėje | 0.487619 |
O čia pačios ROC kreivės: