Analizė
Mūsų aplinka pilkesnė nei prieš 15 metų
Ar pastebėjote, kad interjero dizaine per pastaruosius 15-20 metų visai dingo spalvos ir viskas tapo tik vienodai pilka ir rusva? Na, bent jau man taip pasirodė, tad pagalvojau šią hipotezę patikrinti: paėmiau svetainėje interjeras.lt publikuotų privačių būstų interjerų nuotraukas ir iš jų ištraukiau dominuojančias spalvas. Lyginant 2007-2010 ir 2021-uosius metus iš tiesų galima matyti užslinkusią pilkumą. Tiesa, gal šiek tiek spalvų gal jau grįžta, 2022-ieji buvo kiek spalvingesni, nors tipinis šiuolaikinis interjeras lyg vienu kirviu tašytas. Skaityti toliau…Stephen Few: „Show Me the Numbers“
Nors ši knyga išleista prieš maždaug dešimtį metų, ji išlieka vienas geriausių grafikų bei lentelių dizaino vadovėlių. Joje viskas paprastai paaiškinta su galybe pavyzdžių, ir, kas labai svarbu, viskas puikiai pritaikoma. Autorius teigia, kad visi pavyzdžiai jo knygoje daryti Exceliu, bet knygoje kalbama apie principus, o ne apie technines detales, tad knygoje išdėstytos žinios pravers kiekvienam. People who can’t tell their stories in understandable ways are either naive (unaware of the world outside of their own small spheres), lazy (unwilling to craft the story in familiar terms), full of themselves (more interested in impressing than communicating), unskilled in the use of everyday language, or just don’t understand their stories well enough to tell them clearly. Skaityti toliau…Carl Bergstrom, Jevin West: „Calling Bullshit“
Ši knyga – neblogas kritinio mąstymo vadovėlis, kurį vertėtų perskaityti kiekvienam analitikui ar šiaip sveiko proto dar nepraradusiam žmogui. Dabartiniame „fake news“ ir netikinčių mokslu pasaulyje išlaikyti kritinį mąstymą yra ypač svarbu: jei tik neabejodamas priimsi visokias nesąmones, kurios sklinda socialiniais tinklais ar žiniasklaidoje, greitai įtikėsi visokiomis keisčiausiomis sąmokslo teorijomis ir driežažmogiais. Knygoje aprašoma daug įvairių pavyzdžių, kai visiškai nepagrįsti teiginiai gali skambėti autoritetingai. Jei kas pasakys, jog kairiarankiai suvalgo žymiai mažiau apelsinų nei dešiniarankiai, (visiškai išgalvotas faktas, kurį ką tik sukūriau) tikriausiai nepatikėsite, bet jei kas teigs, jog britų mokslininkai, ANOVA metodu tirdami kairiarankius nustatė, jog su F=4. Skaityti toliau…Kur Lietuvoje tolimiausia iki ežero?
Kartais būna taip, kad kažkur netyčia nugirsti kokią minties nuotrupą ir po to ji vis tavęs nepalieka. Taip ir man nutiko: prieš kokį pusmetį ar net metus kažkas kažkur paklausė, kaip būtų galima sužinoti, kur yra artimiausias ežeras. Pagalvojau, kad atsakymą nesunku surasti šiek tiek pakračius atvirus geografinius ežerų duomenis. Bet tada pradėjo kirbėti nauja mintis: o kuri Lietuvos vieta yra toliausiai iki bet kokio ežero? Aišku, bėgo mėnesiai, programuoti nesiėmiau, bet klausimas vis tiek niežtėjo. Skaityti toliau…Kelios mintys apie Baltarusiją
Kaip ir daugelis, stebiu, kas dedasi Baltarusijoje – socialinis Lukašenkos kontraktas su tauta baigėsi, meilės nebeliko, rinkimus klastoti tapo sudėtingiau. Ne pačią mažiausią rolę šiuose įvykiuose suvaidino ir COVID: virusas atnešė ekonominius sunkumus, o prasta valdžios reakcija jį suvaldant perpildė kantrybės taurę. Virusas geopolitikoje dar gali atnešti nemažai pokyčių. Vienur tai perauga į neramumus, kitur – į naujas ambicijas, tikintis, kad pasaulis užsiėmęs kitais reikalais ir nesureaguos. 2020-ieji gali būti panašaus lūžio metai kaip 2008-ieji. Skaityti toliau…Machine learning’o projektuose sunkiausia ne techninė dalis
Buvęs LinkedIn duomenų analitikas Peter Skomoroch konferencijoje Strata skaitė neblogą pranešimą apie tai, kas sunkiausia įgyvendinant machine learning ar dirbtinio intelekto projektus. Ne, ne techninės kliūtys. Sunkiausia tai, kad labai sunku tokius projektus tiksliai suplanuoti ir subiudžetuoti – o ir jų nauda dažnai sunkiai įvelkama į skaičius (kvantifikuojama). Didelei korporacijai, kurioje visi įpratę IT projektus vykdyti griežtai subiudžetuotais projektais (nesvarbu, kad dauguma jų tuos biudžetus vis tiek ryškiai perlipa), sunku suprasti, jog beveik neįmanoma suprognozuoti, ar veiks algoritmas ar ne, bei kiek laiko užtruks jį ištreniruoti. Skaityti toliau…Duomenys nebūtinai sukuria daug verslo vertės
Šiandien užtikau gerą straipsnį apie tokį požiūrį, su kuriuo, deja, gana dažnai susiduriu kompanijose: reikia surinkti kuo daugiau duomenų, viską bet kaip sudėti į duomenų bazę ir iš to vis tiek gausis kas nors gero. Na, žinai, gi ten machine learning, dirbtinis intelektas, visa kita gi šiais laikais. Svarbu duomenų būtų. Didesnėse kompanijose tai dažnai galima suprasti: pinigų projektams kaip ir yra, norisi užsidėti varnelę, kad „kažką darai su dirbtiniu intelektu“, net jei ir nieko nesigaus, tai bent jau bandysi. Skaityti toliau…Duomenų bazių testavimas
Prieš keletą dienų užtikau patikusį straipsnį apie automatizuotus duomenų bazių testus. Programiniam kodui jau senokai tapo įprastinė praktika rašyti testus, bet duomenų bazių struktūra testuojama ne visada. Tiesa, gerai sutvarkytoje duomenų bazėje įmanoma sudėti daug saugiklių: stulpeliams uždėti apribojimus, išorinius raktus ir panašiai, tačiau bendras požiūris į duomenų teisingumą bei validumą vis tiek reikalingas. Autorius siūlo duomenis testuoti trijose vietose: pirminių šaltinių lygyje, tik juos sukėlus į duomenų bazę ir jau po verslo logikos transformacijų. Skaityti toliau…Ar jums tikrai reikia besimokančių (machine learning) sistemų?
„Žiūrėk, turim duomenų, gal galėtumėt ką nors padaryt su machine learning ar dirbtiniu intelektu? Juk čia gi dabar ateitis“ – labai dažnas šiuolaikinis prašymas iš potencialių klientų. Neretai pasirodo, kad realių problemų sprendimui nereikia nei gudrių algoritmų, nei dirbtinio intelekto: didžioji vertė iš duomenų išspaudžiama žymiai paprastesnėmis priemonėmis, vien tik sutvarkius duomenis ar pasinaudojant senais gerais statistikos įrankiais. Kita vertus, logistinės regresijos terminai panašiai kaip ir bet kokios diskusijos apie neuroninius tinklus: nei apie vienus, nei apie kitus nedaug kas girdėjęs. Skaityti toliau…Neapdorotų duomenų nebūna
Yra toks gana gajus mitas, kad turint „žalius“ neapdorotus duomenis, galima nesunkiai padaryti objektyvias išvadas – juk neapdoroti duomenys turėtų kalbėti už save, jie neturėtų būti „sutepti“ šališkos žmogiškos nuomonės bei išankstinių nusistatymų. Kuo daugiau neapdorotų duomenų, tuo objektyvesnės išvados. Deja, visiškai neapdorotų duomenų nebūna. Jau pats faktas, kad kažkas juos rinko, reiškia, kad kažkas padarė sprendimą jais domėtis: o kodėl rinko būtent taip, o ne kitaip? Kodėl rinko tokius, o ne anokius? Skaityti toliau…Geriausias konkurencinis pranašumas skaičiais neišmatuojamas
Keletas gerų minčių iš David Perell Twitterio apie marketingą ir verslo metrikas: The invention of the spreadsheet transformed marketing and corporate decision making. We’re over-reliant on numbers and metrics. We assume that only what we can measure is real and everything that is real can be measured. One writer calls this the Arithmocracy: a powerful left-brained administrative caste which attaches importance only to things which can be expressed in numerical terms or on a chart. Skaityti toliau…Lietuvos miestų gatvės pagal pasaulio šalis
Neseniai užtikau įdomią JAV bei kitų pasaulio didmiesčių gatvių orientacijos analizę, darytą vienu mano mėgstamiausių python modulių osmnx. Kadangi kodas viešas, tai buvo nesunku tą patį padaryti ir Lietuvos miestams. Kaunas ir Vilnius – gana chaotiški, o kitur vyrauja aiški kvartalinė sistema Kuo senesnis miestas, tuo didesnis senamiestis, o šie dažniausiai būna chaotiški. Naujesniuose miestuose daugiau vyrauja aiški kvadratinė kvartalinė sistema. Buvo įdomu tai, kad dažniausiai ji ne tiksliai šiaurės-pietų bei rytų-vakarų krypties, o apie 20 laipsnių pasukta pagal laikrodžio rodyklę (Alytus, Gargždai, Kretinga, Kėdainiai, Marijampolė, Mažeikiai, Neringa, Palanga, Telšiai – ypač Žemaitijoje). Skaityti toliau…Wexler, Shaffer, Cotgreave: The Big Book of Dashboards
Dirbant su duomenimis ir neturint didelės menininko gyslelės man kartais trūksta teorinių žinių apie grafikų dizaino teoriją, spalvas bei bendrą „user experience“. Kai greitai sumetinėji grafikus Excelyje, tai gal tai ne taip stipriai jaučiasi, bet kai reikia sukurti kažką sudėtingesnio, reikia ieškoti pagalbos knygose. „The Big Book of Dashboards“ pradžiai tam visai tinka. Knygos stipriausia dalis yra tie keli skyriai apie pagrindus: kodėl niekada nereiktų naudoti skritulinių diagramų, kodėl reikia žūt būt vengti šviesoforo spalvų (daltonikai jų neskiria), kodėl reikia vengti per didelio informacijos kiekio vienoje vietoje ir panašiai. Skaityti toliau…Ben Goldacre – „I Think You’ll Find It’s a Bit More Complicated Than That“
Ben Goldacre turėjo šventą misiją: laikraščio the Guardian kassavaitinėje skiltyje jis nepailsdamas kritikuodavo žurnalistus bei mokslininkus, kurie nepaisydami statistikos dėsnių ar gerųjų mokslinio metodo praktikų pernelyg greitai peršokdavo prie toli siekiančių išvadų. Kliūdavo daugeliui, net tam pačiam the Guardian laikraščiui. Ši jo knyga yra kassavaitinės skilties straipsnių rinkinys. Mokslinius atradimus padaryti ne taip jau lengva: mokslininkams reikia nemažai statistikos žinių, o jų atradimus, kurie skelbiami moksliniuose žurnaluose, kritiška akimi turi peržiūrėti ir kiti mokslininkai. Skaityti toliau…Ką rodo Mankiw taisyklė Lietuvai? Palūkanos jau per žemos
Penktadienį keletas bendrų draugų susėdo prie stalo padiskutuoti markoekonomikos ir investicijų temomis. Ir nors karščiausios diskusijos virė apie kriptovaliutas, buvo labai įdomu paklausyti Vaido Urbos pasakojimo apie makroekonomines teorijas. Niekad jose gerai nesigaudžiau, tad buvo labia naudinga suprasti, kokie vėjai vyrauja tarp makroekonomistų, ir ką jie prognozuoja artimiausiems metams. Vienas įdomiausių Vaido paminėtų dalykų buvo Mankiw taisyklė. Kai kurie makroekonomistai mano, jog egzistuoja labai paprasta formulė, pagal kurią reiktų valdyti palūkanas: jos gali būti nusakomos formule Skaityti toliau…Savaitė be nuosavo automobilio
Nežinau už kokius nuopelnus, bet šią savaitę buvau pakviestas prisijungti prie Europos judrumo savaitės (European Mobility Week) akcijos #ditchyourkeys ir ištisas septynias dienas atsisakyti savo automobilio. Tiesa, tam kad šis iššūkis nebūtų labai sudėtingas, akcijos rėmėjai Uber, Vilniaus Viešasis Transportas, Cyclocity, Citybee bei Spark suteikė galimybę šiomis dienomis jų paslaugomis naudotis nemokamai – tad per šią savaitę galėjau išbandyti visokiausius judėjimo po Vilnių būdus, kuriais iki šiol nesinaudojau. Už Vilniaus ribų šiomis dienomis neplanavau niekur vykti, o pasižiūrėjęs į savo judėjimo istoriją, supratau, kad mano geografija buvo ganėtinai ribota: visą laiką maliausi tarp namų Lazdynuose, senamiesčio ir dviejų klientų biurų. Skaityti toliau…Apie (perdėtą) metrikų svarbą
Vienas svarbiausių dalykų šiuolaikinėje vadyboje – metrikų (KPIs, key performance indicators, pagrindinių veiklo rodiklių) sekimas. Juk jei kažko nematuoji, tai ir negali pagerinti. Iš tiesų, poreikis reguliariai matuoti savo progresą organizacijas priverčia rimčiau pažiūrėti į savo duomenų ūkį, mat iki tol duomenų surenkama mažai ir ne daug kam rūpi jų kokybė. Ir tik turint pakankamai duomenų palaipsniui galima prieiti prie „data-driven“ kultūros: visus svarbesnius sprendimus priimti vadovaujantis nebe nuojauta, o paanalizavus objektyvius skaičius. Skaityti toliau…Keletas patarimų apklausų sudarytojams
Artėjant tam pavasario metui, kai į elektroninį paštą bei _Facebook’_o srautą pradeda plaukti studentų prašymai užpildyti nuobodžias ir skausmingai ilgas bakalaurinių ar magistrinių darbų anketas, užtikau labai neprastą „Partially Derivative“ podcast‘o seriją apie tai, kaip teisingai tas apklausas sudarinėti. Kadangi patarimai buvo vertingi ir man pačiam, dalinuosi trumpa jų santrauka: Prieš sudarant apklausos anketą reikia gerai pagalvoti, kokius duomenis nori surinkti ir kaip tuos duomenis analizuosi. Visai ne pro šalį būtų iš anksto susidaryti sąrašą grafikų, kuriuos norėsi nupiešti ir nuspręsti, kokias regresijas skaičiuosi. Skaityti toliau…Robotas irgi žmogus
Iš pažiūros duomenų analizė yra labai nešališkas ir objektyvus reikalas: paimi krūvą duomenų, perleidi per sudėtingą statistinių algoritmų mėsmalę ir gauni kažkokias įžvalgas. Mūsų produktą labiau mėgsta Marijampolėje, brangesnius produktus moterys perka savaitgaliais, socialiniuose tinkluose sekantys veikėją X skaito portalą Y, bent tris kartus gavę labai didelę mėnesinę sąskaitą yra linkę perbėgti pas konkurentus. Su regresijomis (ar sudėtingesnėmis analizėmis) ginčytis sunku, nes duomenys lyg ir kalba už save. Nebereikia spėlioti ir remtis dažnai mus pavedančia intuicija. Skaityti toliau…Dear Data,
Vieną Kalėdų senelio dovanotų knygų surijau per vieną vakarą. Dvi profesionalios duomenų dizainerės (net nesu tikras, kaip teisingai vadinti duomenų atvaizdavimu užsiimančiuosius) – viena Londone, o kita Niujorke – ištisus metus kas savaitę viena kitai siųsdavo ranka pieštus atvirukus su duomenų schemomis, diagramomis ir grafikais. Kiekvieną savaitę jos pasirinkdavo vis naują temą – kiek kartų pasakei „ačiū“, kiek kartų per savaitę nusijuokei, kas kabo tavo spintoje, kas yra tavo geriausi draugai, kiek kartų nusikeikei ar kiek išgėrei alkoholio. Skaityti toliau…Ką turi mokėti analitikas
Neseniai iš skaitytojo gavau klausimą: ką turi mokėti analitikas? Klausimas ne toks jau paprastas, nes neužtenka išvardinti kelias programavimo kalbas ar paminėti kelias technologijas: negali būti jokio baigtinio sąrašo prie kurio sudėliojus varneles galėtum sakyti, kad, va, šitas analitikas tikrai yra geras. Juk tai tėra tik įrankiai. Nors daugelis analitiko negali įsivaizduoti be matematikos ar statistikos žinių, manau, kad pati svarbiausia sritis, kurią turi išmanyti analitikas yra verslas, kuriame jis dirba. Skaityti toliau…Antro rinkimų turo prognozė pasitelkiant neuroninius tinklus
Pirmiausia turiu įspėti: nemanau, kad reikėtų į gautus rezultatus žiūrėti labai rimtai. Neuroninio tinklo mokymui naudojau tik 2012-ų metų Seimo rinkimų apygardų duomenis, tad imtis labai nedidelė, o tai turėtų lemti ir gana nemažą paklaidą prognozėse. Galbūt tikslesnių rezultatų būtų galima tikėtis naudojant apylinkių, o ne apygardų duomenis.
Prognozuoti šių metų rezultatus iš 2012-ų metų duomenų nelengva ir dėl stipriai pasikeitusio partijų populiarumo: žalieji valstiečiai prieš ketverius metus nebuvo labai patrauklūs rinkėjams, o ir Skvernelio atsiradimas labai šią partiją pakeitė. Įdomu tai, kad Darbo partijos bei tvarkiečių kritimas iš aukštumų gana gerai atsispindi neuroninio tinklo rezultatuose: jiems prognozuojama laimėti mažiau apygardų nei jie šiuo metu pirmauja. Kad ir kaip ten būtų, gavau tokį rezultatą:
| Prognozė | Dabar pirmauja | |
|---|---|---|
| LVZS | 24 | 21 |
| TSLKD | 24 | 22 |
| LSDP | 9 | 10 |
| LRLS | 5 | 4 |
| LLRA | 3 | 3 |
| TT | 2 | 4 |
| KITI | 1 | 2 |
| DP | 1 | 3 |
| NEP | 2 | 2 |
Neuroninis tinklas „išmoko“, jog stiprus lenkų pirmavimas apygardoje dažniausiai lemia ir pergalę antrame ture. Algirdui Paleckiui pergalė neprognozuojama, nes istoriniai pernai metų duomenys rodo, jog „Frontui“ ne itin sekėsi – bet jo puikus pasirodymas pirmame ture tikriausiai buvo netikėtas ir daugeliui politikos analitikų. Keisčiausia prognozė, kuria sunku patikėti yra 52-oje Visagino-Zarasų apygardoje, kurioje antrame ture kausis Darbo partija su tvarkiečiais (pergalė prognozuojama Darbo partijai, nors stipriai pirmauja tvarkietis Dumbrava). Keistoka, bet gal ir logiška 40-osios Telšių apygardos prognozė, kur stipriai pirmaujantis darbietis turi mažai šansų atsilaikyti prieš valstietį Martinkų. Kaip jau minėjau, Darbo partijai šis modelis daug šansų nepalieka. Visas apygardų sąrašas su prognozuojamais nugalėtojais ir tikimybėmis, kad nugalės pirmaujantis.
Turint nedaug istorinių duomenų tikriausiai labiau pasitikėčiau politikos ekspertų prognozėmis konkrečioje apygardoje arba modeliuočiau tikimybes kiek kurios partijos rėmėjų ateis į antrą turą bei palaikys ne savo partijos kandidatą: būtent tokį modelį ruošia WebRobots komanda, kuri leido man pasinaudoti jų surinktais iš VRK duomenimis. Idėja patreniruoti neuroninį tinklą ir kilo susidūrus su problema ar nebūtų galima kaip nors statistiškai išskaičiuoti tikimybių, kiek, tarkim, socialdemokratų palaikytų konservatorių kandidatą jei jis būtų likęs prieš darbietį. Taip pat galima pažiūrėti į Vaidoto Zemlio prognozes.
Post Mortem
Rezutatai buvo stipriai kitokie, nei buvo tikimasi: daugiausiai prašauta (tikriausiai dėl to, kad 2012-aisias valstiečiai pasirodė ne itin įspūdingai) su LVŽS ir TSLKD. Tam tikros tendencijos buvo teisingos – Darbo partija, Tvarka ir Teisingumas bei Socialdemokratai iš tiesų gavo mažiau mandatų nei buvo pirmaujama po pirmo turo, tuo tarpu liberalai sugebėjo laimėti daugiau apygardų nei pirmavo po pirmo turo, tačiau šių pokyčių mastas buvo žymiai (žymiai žymiai) didesnis. Iš viso, neuroniniai tinklai sugebėjo atspėti 48 apygardas (67% tikslumas). Palyginimui – rankomis dėliotas Webrobots komandos modelis pasiekė 80% tikslumą. Tiesa, atmetus kai kuriuos nelogiškus neuroninio tinklo siūlymus, kurie plika akimi atrodė keisti ir pataisius prognozę Dainavos apygardoje dėl Vinkaus skandalo (ko iš 2012-ųjų duomenų niekaip nebuvo galima žinoti), buvo galima pasiekti maždaug 75% procentų tikslumą. Ne kažką, bet šis tas.
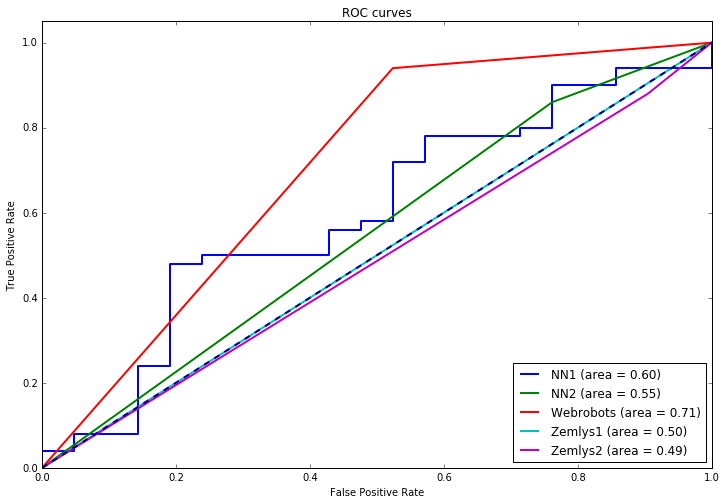
Skaičiuojant modelio patikimumą, dažnai žiūrimas plotas po Receiver Operating Characteristic (ROC) kreive (kuo gerenis modelis, tuo jis turėtų artėti link vieneto). Štai modelių palyginimai:
| Area under ROC curve | |
|---|---|
| Neuroninis tinklas (tikimybės) | 0.597143 |
| Webrobots modelis | 0.708095 |
| Neuroninis tinklas (binarinis) | 0.549048 |
| Laimės pirmaujantis 1 ture | 0.500000 |
| Laimės pirmaujantis daugiamandatėje | 0.487619 |
O čia pačios ROC kreivės: